Zotero is a cross-platform literature manager that is able to sync to a remote server and across multiple user devices. There are many alternatives available, each with strengths and weaknesses, but I am currently using Zotero to manage my literature because it is free and works with WebDAV for additional free storage.
In this article I will describe why optical character recognition (OCR) is important for Zotero and suggest a way to add OCR to existing items in a Zotero library. However, the method actually works for any collection of PDF files on your computer!
The reason for OCR in Zotero
Zotero has a nice “Retrieve Metadata for PDF” feature that automatically scans a PDF file for metadata and then uses it to search for matching bibliography information from Google Scholar. The PDF is then nested under a parent item that is (usually) properly indexed in the internal Zotero SQLite database.
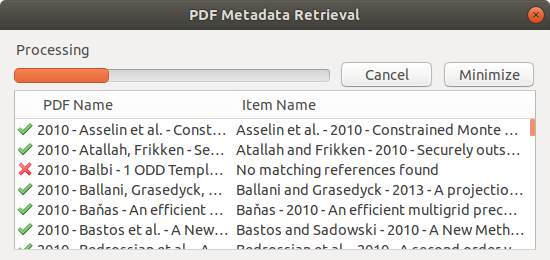 In this case Zotero found matches for most of the items. The one with the red cross appears not to be a journal article or book, but some other random (non-public) document that at some time was imported into my library.
In this case Zotero found matches for most of the items. The one with the red cross appears not to be a journal article or book, but some other random (non-public) document that at some time was imported into my library.
However, if the PDF does not contain an OCR layer this feature does not work. This is often the case for older journal articles, or PDFs that were scanned from a hard copy.
If you manage a large literature library then you might have many non-OCR files in there, which are not properly indexed. Manually creating a parent item for each of them is laborious. The only practical approach is to add an OCR layer to the PDF files.
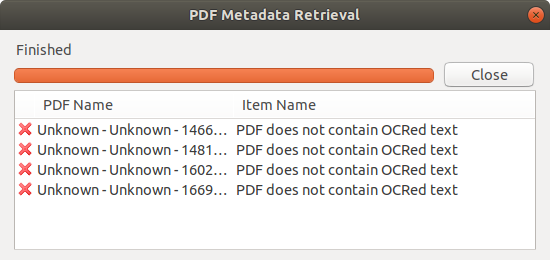 Example errors when Zotero is unable to find an OCR layer in a PDF document during attempted metadata retrieval.
Example errors when Zotero is unable to find an OCR layer in a PDF document during attempted metadata retrieval.
Adding OCR to PDF files
There are a number of commercial, free and open source options for adding OCR to PDF files. Most famous of these is the Adobe Acrobat reader, which at the time of writing requires a monthly subscription to an “Edit” feature extension to unlock the OCR capabilities. If you have this available to you, please go ahead and use it.
If you prefer a free option there are a few available, but I had most success with ocrmypdf, written by James R. Barlow and release under the GNU GPLv3 license.
The following steps should help you get started with ocrmypdf and use it to fix those annoying OCR problems in Zotero.
Installing ocrmypdf
Linux
I am using Ubuntu 18.0.4.1LTS. Before using apt-get to install ocrmypdf, it was necessary to allow additional software to be installed
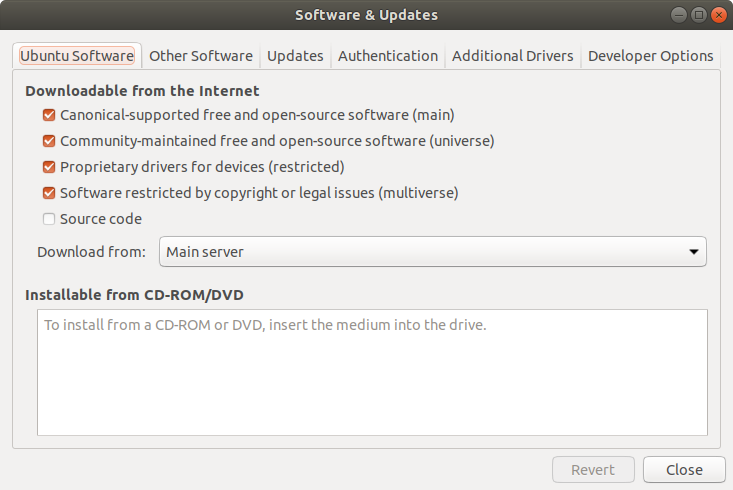 Ubuntu software repository options.
Ubuntu software repository options.
Then you should be able to do:
sudo apt-get install ocrmypdf
For more installation information please visit the project page.
General usage
On the command line terminal you can simply provide ocrmypdf with an input PDF file and the desired output file.
ocrmypdf input.pdf output.pdf
If successful, this creates a new file called output.pdf, which is a modified version of the original. The new file should hopefully contain an OCR text layer!
Usage with Zotero
My aim here is to describe a method for parsing through a large Zotero library, checking for files without an OCR layer and then adding one on the fly. We will eventually write abash script to control this, but first I will explain how individual steps in the script work.
One-liner for a single file
In this crude example I have created a new folder called /home/simon/Zotero/ocr/. The Zotero storage folder is in /home/simon/Zotero/storage, or simply ../storage/
The following allows you to find a file using a search string, for example here the filename ends with ” – kittel.pdf.pdf”. I am assuming there is only one file that matches this search string!
INPUT=`find ../storage/ -name "* - kittel.pdf.pdf"`; ocrmypdf "$INPUT" output.pdf
You can then check the output.pdf manually then replace the original.
If you are feeling really brave, and wish to do this on the fly, without checking the new PDF file first, you can automatically replace the input file directly in the Zotero storage folder.
INPUT=`find ../storage/ -name "* - kittel.pdf.pdf"`; ocrmypdf "$INPUT" output.pdf; mv output.pdf "$INPUT"
I did not have any issues with this approach as ocrmypdf doesn’t seem to be destructive, but care should be taken when automatically replacing or deleting files! In the final script below I take a few rudimentary precautions in that sense!
Check if a file has OCR
We are going to approach this method on the bash command line. To that end we can use pdffonts to check whether a PDF document contains OCR. pdffonts checks if the file contains embedded fonts. Any PDF without OCR text will contain zero embedded fonts, while a file with an OCR layer will have 1 or more embedded fonts.
For example, this file does have an OCR layer:
$ pdffonts output2.pdf
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
JKMERI+GlyphLessFont CID TrueType Identity-H yes yes yes 9 0
QMAGQI+GlyphLessFont CID TrueType Identity-H yes yes yes 20 0
MEMQSK+GlyphLessFont CID TrueType Identity-H yes yes yes 38 0
So does this one:
& pdffonts Unknown\ -\ Unknown\ -\ Chapter\ 28\ –\ Magnetic\ Fields\ Sources\ Goals\ for\ Chapter\ 28.pdf
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
ABCDEE+Calibri TrueType WinAnsi yes yes no 5 0
ABCDEE+Calibri CID TrueType Identity-H yes yes yes 7 0
Times New Roman CID TrueType Identity-H yes no yes 14 0
Times New Roman TrueType WinAnsi no no no 19 0
Times New Roman,Bold TrueType WinAnsi no no no 30 0
Symbol CID TrueType Identity-H yes no yes 32 0
Times New Roman,Italic TrueType WinAnsi no no no 55 0
ABCDEE+Trebuchet MS CID TrueType Identity-H yes yes yes 73 0
ABCDEE+Trebuchet MS TrueType WinAnsi yes yes no 78 0
When there is no OCR there will be no embedded fonts found:
$ pdffonts Book3.pdf
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
Basically, we could determine whether the file has OCR by counting the lines of the output, or we can grep the output and count occurences of the string “Type”. Here we found 7 fonts:
$ pdffonts input.pdf | grep "Type" | wc -l
7
A slight problem with this approach is that some downloaded papers have no OCR layer for the actual, useful text, but a layer is added for a watermark layer by the publisher’s website on download. In this case a font will be found:
 Paper downloaded from AIP website has a useless OCR layer added just to watermark the download event. This is an attempt to limit piracy but doesn’t help the user at all.
Paper downloaded from AIP website has a useless OCR layer added just to watermark the download event. This is an attempt to limit piracy but doesn’t help the user at all.
$ pdffonts "$INPUT"
name type encoding emb sub uni object ID
------------------------------------ ----------------- ---------------- --- --- --- ---------
Helvetica-Bold Type 1 WinAnsi no no no 5 0
Perhaps we can change our search rule to require more than one embedded font, but I have not yet ruled out the possibility that genuine, useful OCR might mean only one PDF font is present in the file.
A script
Pulling it all together, the following prototype bash script will find a list of files that match a specific string, then loop through them checking if they are missing OCR. If they are, it will call ocrmypdf on them. By removing any existing temp.pdf file before calling ocrpdf we eliminate some of the risk of replacing our original files with a corrupted output file. That being said, please use it with caution and at your own risk!
#!/bin/bash
find ../storage/ -type f -name "Unknown - Unknown - 1*.pdf.pdf" -print0 |
while IFS= read -r -d '' file; do
# Remove any existing temp.pdf. This should stop your db file from being overwritten with the previous one, in case of an error.
if [ -f ./temp.pdf ]; then
rm ./temp.pdf
fi
printf '%s\n' "$file"
num=`pdffonts "$file" | grep "Type" | wc -l`
if [ $num -lt 1 ]
then
echo "File has no OCR so let's do it..."
ocrmypdf "$file" ./temp.pdf
# Use this with extreme caution: This should only execute if temp.pdf was successfully created.
if [ -f ./temp.pdf ]; then
mv ./temp.pdf "$file"
else
echo "OCR was unsuccessful so not updating file! "
fi
fi
done
Once files have had OCR added, you can call the Metadata extraction tool in Zotero.
Summing up
In my experience, ocrmypdf did an excellent job of adding OCR to journal articles. Sometimes Zotero was unable to identify enough of the metadata from the newly added text to get a positive match from Google Scholar, but this is mostly an issue with Zotero, not the OCR, and a parent item with at least the authors and title were created, making indexing far better than it was before.
When I checked, a lot of other items in my library also did not have the full metadata included in the parent item, so it is always better to import a full, proper bibliography entry from an external source than to rely on Zotero to extract meta data. However, if this is not possible, say you imported a load of PDF files given to you by a friend or colleague, the ability to add OCR is a massive help.